

- 読書の記録(ブクログ)
- booklog.jp/users/nekohon
- 写真・その他(Tumblr)
- https://nekotubuyaki-blog-blog.tumblr.com/
- Nostr
- npub1gum3wnexxg4qqxrnvcgzgrwdm6qusqketj7xcyqpkq4wurk8udys5lxlvn
- Bluesky
- nekotubuyaki.bsky.social
たわいもないことをつぶやいています。本を読むと酔っ払うので毎日泥酔状態。夜8時にバッテリーが切れて眠りにつきます。
For languages other than Japanese, I use Google Translate.
2022年 11月 に登録
眠っている間に隣国の政治が大変なことになっていた。
ネコ  さんがブースト
さんがブースト
さんがブースト

 )
)
https://x.com/ohtabooks_pr/status/1863434701568197049
マンアフターマン復刊の発表があったのでこっちでも共有
昨日一昨日とあちこち動き回ったからというわけではないのだけれど、今日は体調も今ひとつということもあって、暮らし全体が「凪」の状態です。
1日が日曜日で、月曜日は2日という日付と曜日の並びが、いろいろと勘違いをもたらしそう。
"定紋"ではなくて「縄文」です!間違えました(汗)
QT: https://fedibird.com/@neko_tubuyaki/113574609430001565 [参照]
@neko_tubuyaki@fedibird.com
千葉県の秋(11月) 1.DIC川村記念美術館( https://kawamura-museum.dic.co.jp/ ) 2.千葉ポートタワー( https://www.chiba-porttower.com/ ) 3.加曽利貝塚定紋遺跡公園( https://www.city.chiba....
「DIC川村記念美術館」( https://kawamura-museum.dic.co.jp/ )にて撮影。美術館前の池にはオシドリもきていたようです。(撮影機材:RICOH GR III)
千葉市にある「加曽利貝塚縄文遺跡公園( https://www.city.chiba.jp/kasori/ )」にて。(撮影機材:FUJIFILM FinePix XP140)
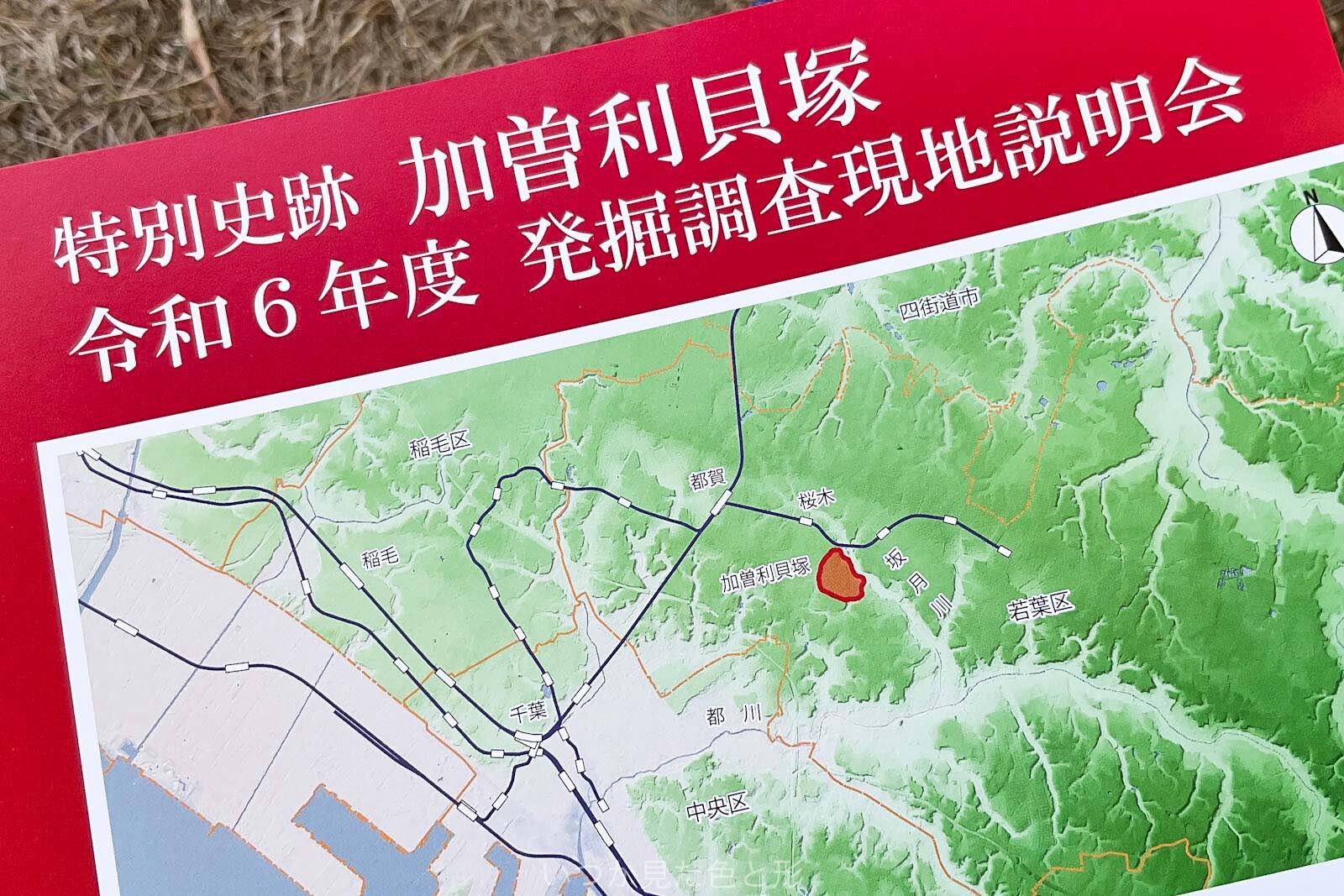
昨日、加曽利貝塚( https://www.city.chiba.jp/kasori/ )で行われた「令和6年度加曽利貝塚発掘調査現地説明会」( https://www.city.chiba.jp/kyoiku/shogaigakushu/bunkazai/eventcalendar_r6gensetsu.html )に行ってきました。専門家の話を聞く機会というのはあまりないし、実際の遺跡・遺構・遺物の生々しさも実感できてとても良かったですよ。
先日、千葉県立美術館( https://www.chiba-muse.or.jp/ART/ )で開催されている『開館50周年記念特別展「浅井忠、あちこちに行く-むすばれる人、つながる時代—」』( https://www.chiba-muse.or.jp/ART/exhibition/events/event-6396/ )。多彩・多才。千葉県立美術館は、ここ数年間を取り上げてみても結構いい企画展が続いていると思いますよね。(2枚目の写真は白黒画像になっていますが、実物はフルカラーで印刷された掲示物です)
千葉県の秋(11月)
1.DIC川村記念美術館( https://kawamura-museum.dic.co.jp/ )
2.千葉ポートタワー( https://www.chiba-porttower.com/ )
3.加曽利貝塚定紋遺跡公園( https://www.city.chiba.jp/kasori/ )
4.千葉市都市緑化植物園( https://www.toshiryokka.jp/ )
(撮影機材:FUJIFILM FinePix XP140、RICOH GR III)
朝食が手羽元カレーと納豆で、胃腸内がしっちゃかめっちゃかな朝。
えー……帰宅しました。庭園(紅葉)→植物園(サザンカ)→美術館(日本画)→博物館(縄文遺跡)と回りました。情報過多で脳みそが疲れ果てております。
ネコ
さんがブースト
さんがブースト

メディアの保存には、Mastodonのプログラムを置いて実行しているサーバのローカルストレージに直接保存する方法の他、オブジェクトストレージという、メディアを保存する専用の保管場所を使うこともできます。
ローカルストレージを使った方法は、別途サーバを用意する必要がないこと、仕組みが単純なことから、設置・提供が簡単というメリットもありますが、
メディアは大量に保存され、保存容量がどんどん増えていくため、
ストレージが不足してエラーになり、その際にサーバプロセスも巻き添えにして全部に影響を与えてしまう問題、
サーバの処理負担の増大とトラフィックが多くなる(転送量課金されるとサーバで特に厳しい)問題、
サーバが大きくなってきた時に、複数のサーバで構成しようと思っても、特定サーバのストレージに依存していることで台数を増やせない(スケールアップできない)問題などがあり、
大量のデータを保存しても自動拡大し(事実上、お金を払えば無限に保存できる)、サーバプロセスとは分離した保管場所として、オブジェクトストレージを利用することがあります。
AWS(S3)やAzure、GCP、Wasabi、Cloudflare R2、VPS業者提供のものなどがよく利用されています。
Misskeyなども事情は同様です。
ネコ
さんがブースト
さんがブースト
Mastodonは、サーバが利用者を守る設計になっています。
利用者の代わりに、サーバがリモートの情報にアクセスし、適切な変換をかけ、それを提供します。
サイズが大きすぎれば縮小し、一般的でない形式は扱える形式に変換し、サムネイルやブラーハッシュを生成して軽量に内容を確認できるようにします。
悪意あるメディアはブラウザをクラッシュさせるかもしれませんし、規格外のデータは、利用者の帯域(とくにモバイル)を大量消費したり、相手サーバの応答が遅ければクライアントの動作に悪影響を与えることもあります。
また、事前に代理取得しておくことで、いつアクセスしたか、誰がアクセスしたかをリモート側に悟られないよう隠蔽し、アクセスするブラウザの脆弱性などを突かれて不正なプログラムを仕込まれたり、情報が盗まれたり、騙されたりしないようにしています。
これらの処理は、サーバ側では処理や保管に相応の負担を引き受けることになりますが、
クライアントのプライバシーが守られ、安全で楽で快適になりますし、
全クライアントが直接アクセスするより、相手サーバも送信トラフィックが減ることになります。
(他方、CDNやリバースプロキシで軽減できますが、連合したサーバ数だけ同時アクセスが行われる問題はあります)
ネコ
さんがブースト
さんがブースト
WebUIでは『利用できません』という表示とともに、クリックしたときにローカルサーバのメディアプロキシのURLに飛ぶように、添付ファイルの表示を行います。
このプロキシは、クリックしてリクエストされると、そのタイミングでもう一度リモートへメディアを取得しにいき、うまく取得できたらその画像のURLにリダイレクトしてくれます。
うまく取得できたら、サーバ上のリモート画像も保存されるので、次回からは『利用できません』ではなく、ちゃんと画像が表示されるようになります。
誰かが必要としたタイミングでリトライし、復元するための機能です。よくできてますね。
また、未対応形式の場合は、サムネイルは表示できませんが、リモートのURLに直接ジャンプするリンクになります。
相手先のサーバが対応している場合、添付ファイルにはブラーハッシュ(BlurHash)という、画像を極端にぼかしたイメージを再現するためのデータがついています。
サムネイルとしてセンシティブ画像などを伏せる際に使われる他、画像取得中の一時表示、そして取得失敗したときに、画像の代わりに表示します。
ブラーハッシュの実体は短いテキストなので、保存コストがゼロに近く、画像の保存や取得と違い、受け取り失敗することがないため、非常に便利な仕組みです。
ネコ
さんがブースト
さんがブースト
Mastodonの画像処理についてちょっと書いておきましょうか。
まず、Mastodonは、サーバのユーザーが投稿しようとしている画像、リモートからやってきた投稿などについてくるリモート画像を、添付ファイルの保存場所に保存します。
ファイルの取得がエラーになったり、ファイル種別と拡張子がウソだったり、サイズが大きすぎたり、未対応の形式だった場合、
投稿の場合はWebUIやクライアントにエラーを返し、
リモート画像の場合はURLだけ保存して、ファイル未取得の添付ファイルとしてデータベースに記録を保存します。
添付ファイルは通常、APIから取得した場合、様々なメタデータを取得できますが、未取得・エラーの場合はそれを提供できないので、ほとんどがデータなし、ファイル種別は不明になります。
リモートのURLだけは教えてくれるので、クライアントアプリの実装側で、これを直接参照して、うまくいけば画像表示することは可能です。
ただし、Mastodonが通常行う、不正なデータを拒否し、サイズを調整し、必要なら読める形式に画像変換するなど、安全に対する対策が効かなくなります。
そのために直接参照ではなく取得したデータを提供しているので、安直にリモートURLへフォールバックすることはお勧めしません。
街角で、「あっ、納豆の匂いがする」と思って匂いの元をよく探してみたら、それはコーヒー屋さんから漂ってくる匂いで、つまりは、コーヒー豆の焙煎をしている時の香りだった。それに気づいた時には、「バカッ!バカッ!」と、自分をタコ殴りにしたくなったのだけれど、したくなっただけであって、もちろん実際に拳でもって頭を殴りつけたわけではない。食欲をそそる納豆の匂いと焙煎した時のコーヒー豆の香りが隣り合った引き出しに入っている私の嗅覚に幸あらんことを。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- 読書の記録(ブクログ)
- booklog.jp/users/nekohon
- 写真・その他(Tumblr)
- https://nekotubuyaki-blog-blog.tumblr.com/
- Nostr
- npub1gum3wnexxg4qqxrnvcgzgrwdm6qusqketj7xcyqpkq4wurk8udys5lxlvn
- Bluesky
- nekotubuyaki.bsky.social
たわいもないことをつぶやいています。本を読むと酔っ払うので毎日泥酔状態。夜8時にバッテリーが切れて眠りにつきます。
For languages other than Japanese, I use Google Translate.
2022年 11月 に登録
