

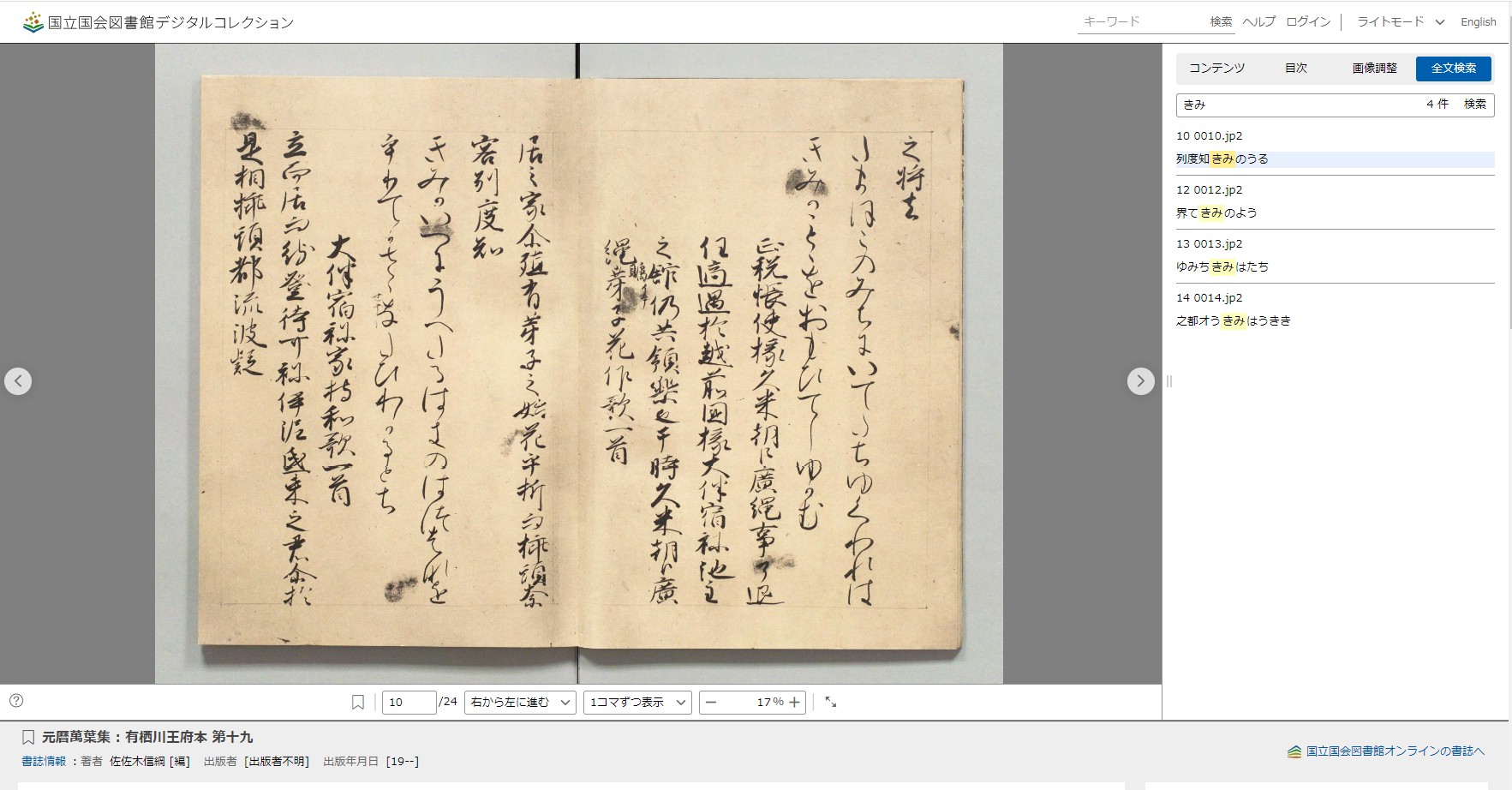
くずし字もある程度OCR化されてるとは恐れ入った。ただ、わりと簡単な文字も間違えてるから信頼はおけないね。
この場合だと、「きみのうる」となってるけど、これは「きみがいへ」。

{kind=link}
{kind=link}
@noki104 AIでくずし字を読めるとかいう話があったと思うんですけど、まだまだ、改良の余地はあるんですね。
@GabbingDog 実はAIはこの手の古めのくずし字は苦手で、江戸時代のものがわりと得意なようです。あと人間が読みにくいものはAIも読みにくいみたいですね。
我々の仕事の一部がAIに取って代わられるというよりは、AIと一緒になって読んでいく、そんな段階です。おそらく今後も似たような状況が続くんだと思います。
@noki104 なるほど。なんとなく、くずし字って、一つの概念で捉えちゃって全部解読できるようになったのかって思ってましたけど、時代や記載された文書の種類によって大きく違ってきそうですよね。
@GabbingDog そうですね。時代・書き手・手書きか印刷か、などでかなり違います。なのでAIの登場ではからずも熟練した読み手の精度の高さが浮き彫りになりました。
こういった技術が発展すると、初学者が読みやすくなり裾野が広がって良いなあと思っています。
@noki104 単語だけでも拾えると、他分野の人でも検索できるので、活用の幅が一気に広がりそうですよね。
古文書を使ったオーロラの研究とかなかなか面白かったです。
@GabbingDog おお!よくご存知ですね!日本書紀の記事が最古の天文記録だったというやつですね。
まさにくずし字OCRの目指すところはそこですよね。某大なテキスト群をひとまず用意できれば、あとはいろんな分野の人と一緒に使い道を考えられると思います。
@noki104 それです!
国文研・極地研・統数研と隣り合ってるんだから、今後も協力しあって楽しい成果あげてほしいですねw

全体のキーワード検索が内容検索に対応していて、タイトルだけじゃなくてキーワードに言及している本もヒットするのが便利(これはこれまでもそうだったかな?)。
大規模なOCR化がされたときにも言われていた気がするけど、簡易的なテキストデータベースとしても使えるね。