
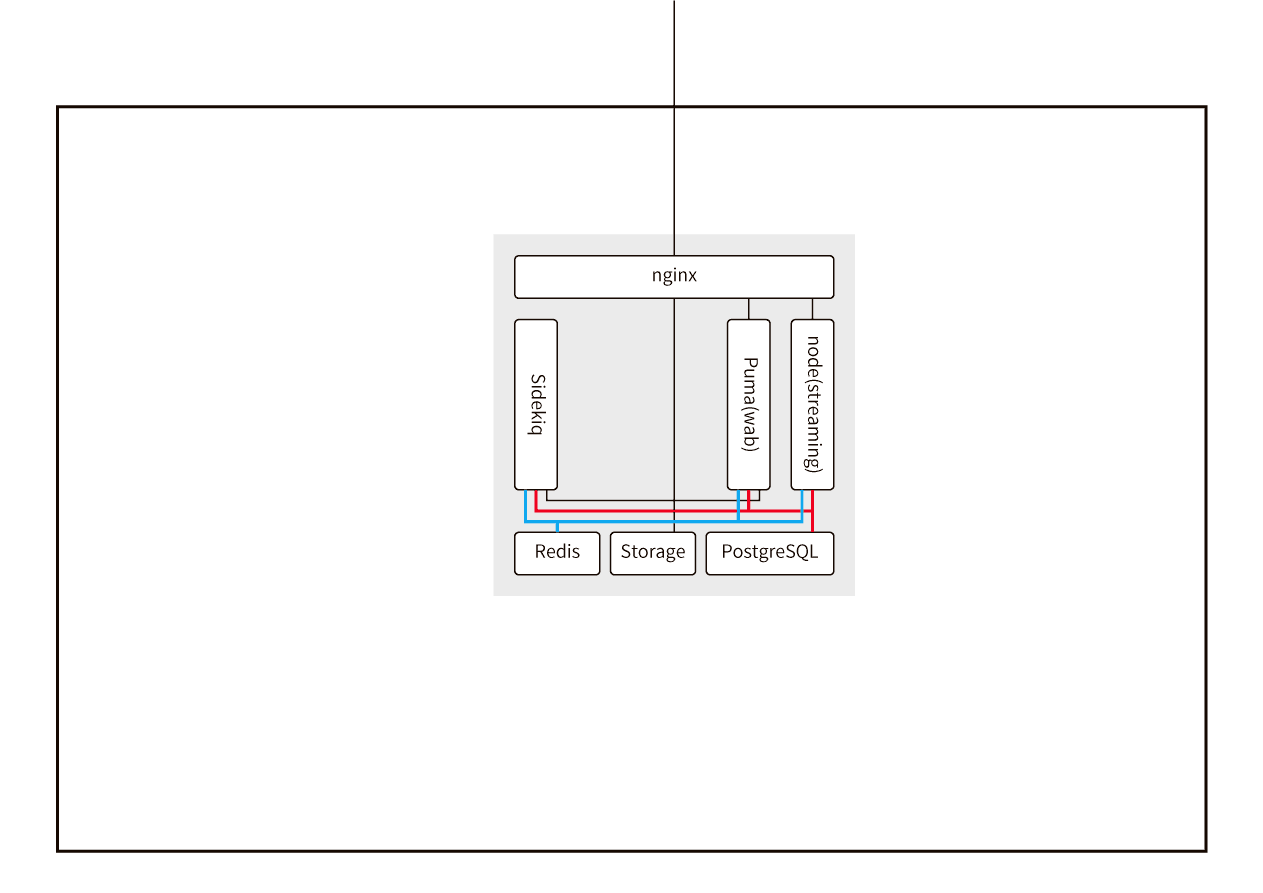
Fedibirdの現在の構成図です。
基本的な構成と比較していきます。
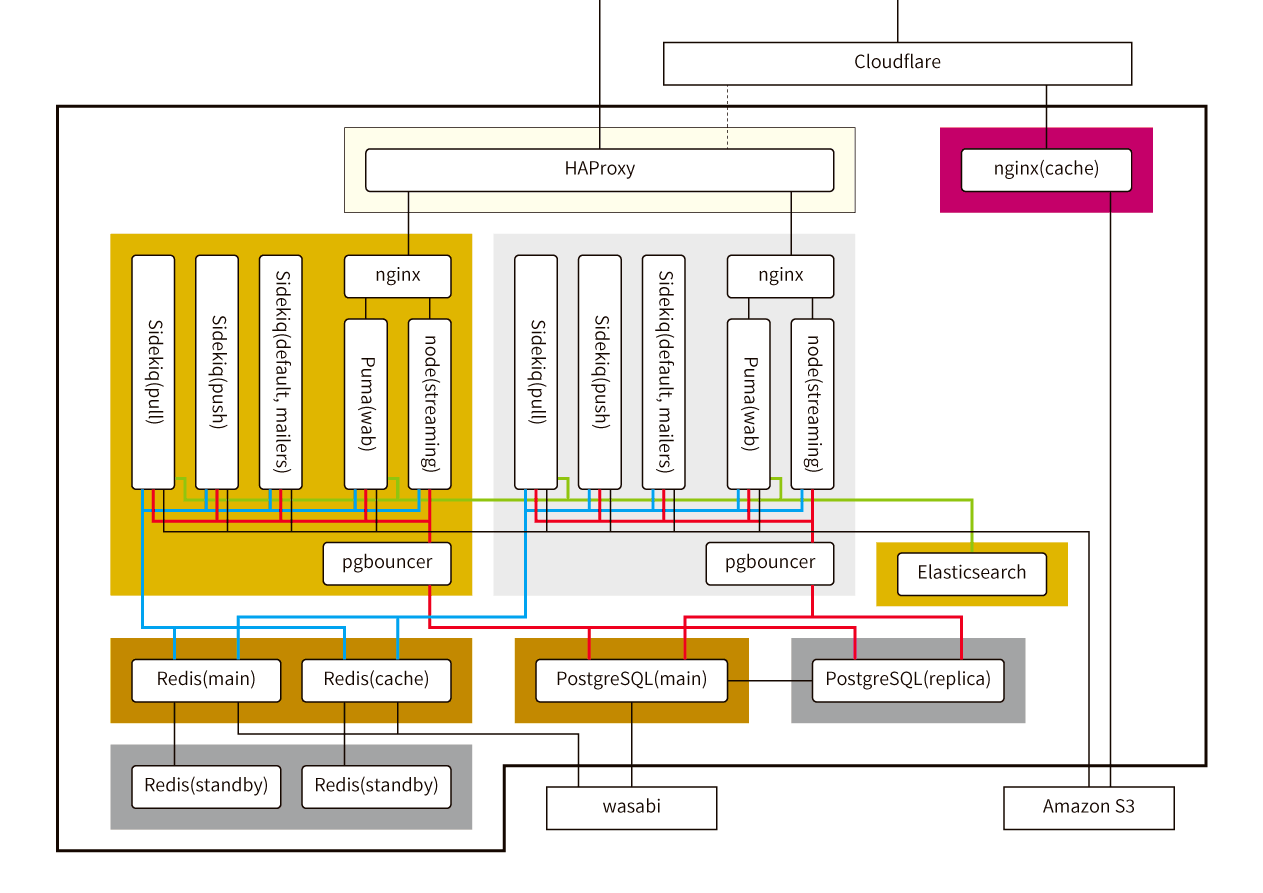
マシンの台数を増やしています。同じ構成のサーバを2台置いて、負荷の分散・処理能力の増強、片方が落ちてもサービスが停止しないように構成しています。
データベース(PostgreSQLとRedis)は、2台が同じものを参照する必要があるので、別のマシンに分けて実行しています。
Storageは、ローカルファイルシステムだと両方のマシンから読み書きできないので、外部のオブジェクトストレージ(Amazon S3)に変更しています。
Sidekiqは、キュー毎にプロセスを分離しています。
PostgreSQLへ同時接続するプロセスがどんどん増えていくので、pgbouncerを経由して接続することで、PostgreSQL側の接続数を一定以内に制限し、接続を再利用することで効率化しています。
2台の手前にHAProxyを置いて、外部からは一つのサーバに見えるようにして、2台のサーバに接続を分散させます。
全文検索用にElasticsearchを追加しています。
あとは、二重化したりバックアップする機構です。
@super All configurations are without Docker.

@noellabo I see this Architecture may require modifying official code base, such as separating sidekiq read and write, which is not easy for most of admin. Anyway it looks super strong and solid and maybe we don’t need that until got 10k+ active users.
@super Fedibird has 1,082 registered users and about 600 active users. The current number of processes on sidekiq is default x 4, push x 2, pull x 2, and two VPSs with the same configuration, totaling 16 processes. If you want to scale this further, you'll probably have multiple servers handling only sidekiq. Currently, I have a little extra processing power.
Bigger server admins said redis would be a bottleneck.

{kind=link}
{kind=link}
@noellabo What's the benefit of haproxy and multiple nginx instances? My architecture is very similar except only one nginx instead of haproxy (and no cloudflare).
@Gargron We have two Mastodon services running in the same configuration, but each running on a different operator's VPS.
This VPS is maintained so that Cloudflare and HAProxy can be shut down and run independently at any time. It can be directly referenced to isolate failures or to perform experiments in a production environment.

@noellabo is there any node such as puma process using docker image?