
llama.cppのcliで日本語通すにはどうすればいいんだっけ。ああうざい…
llama-cli.exeに日本語通すには。UTF-8なテキストファイルにシステムプロンプト書いて-fパラメータにパス指定。
https://huggingface.co/tiiuae/Falcon3-10B-Instruct-1.58bit
Falcon3-10B-Instruct-1.58bitというBitNetモデルが賢いらしいと聞いたので、今慌てて評価してるところ。
BitNetの推論アプリはllama.cppの改造版なので、-pに指定した日本語が通らんとか、めんどくささがある。
それとバイナリがCPU版だから遅いなぁ。自分でビルドしなきゃいけないか。軽い評価だけならCPUでもいけるが、10Bモデルだと1.58bit量子化モデルといえ、3GB超えるし、そこそこ遅いんだよね。
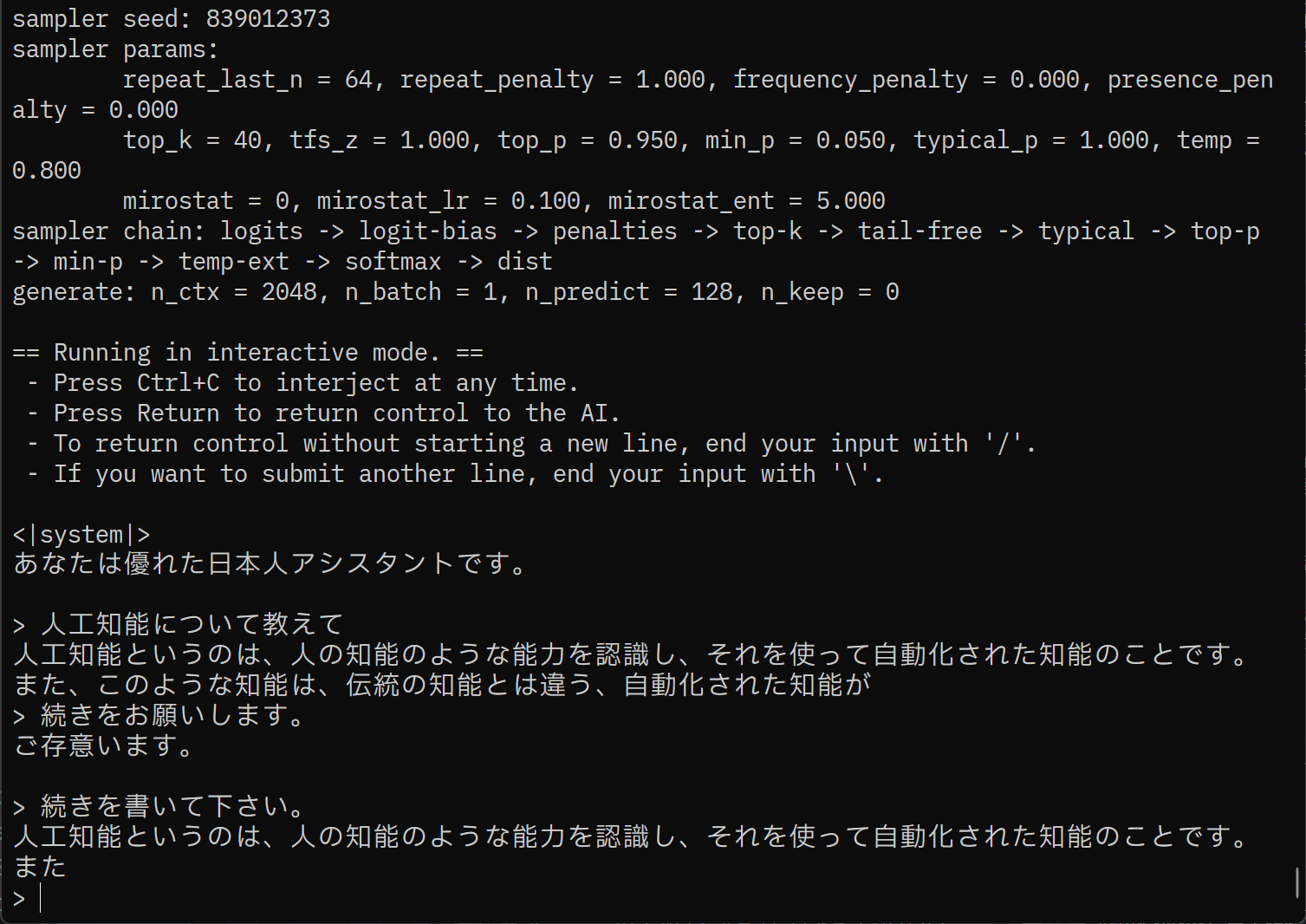
とりあえずシステムプロンプト「あなたは優れた日本人アシスタントです。」した限りでは、日本語の意味の通る文章が辛うじて出力できるかな、レベルだった。
ただ、このFalcon3-10B-Instruct、4bit量子化とかではどんな性能かはまだ見てないから、まだBitNetによる性能劣化レベルについてはなんとも言えない。
Falcon3-10B-Instruct-1.58bitはこんな感じ。まあ、想像通り、使い物になるレベルではない。
今、4bit量子化モデルを落としてきてるので、それも試してからBitNetの最終評価をしようと思う。
{kind=link}
手元のバイナリではfalcon3が動かんから落としてきたらdefenderでマルウェア検出されて消された。うざすぎる。
https://github.com/ggerganov/llama.cpp/issues/10768
これとは違うやつだが、b4351でもTrojan:Script/Sabsik.FL.A!mlというのが検出される。
https://github.com/ggerganov/llama.cpp/pull/10876
llama.cppのfalcon3サポート、バグがあったらしくて、差し戻されとる…なんてことだ。
萎えたので、すべてを忘れて、何もかもなかったことにしよう…
ここまでやったんだし、結局b4350をダウンロードして試した。
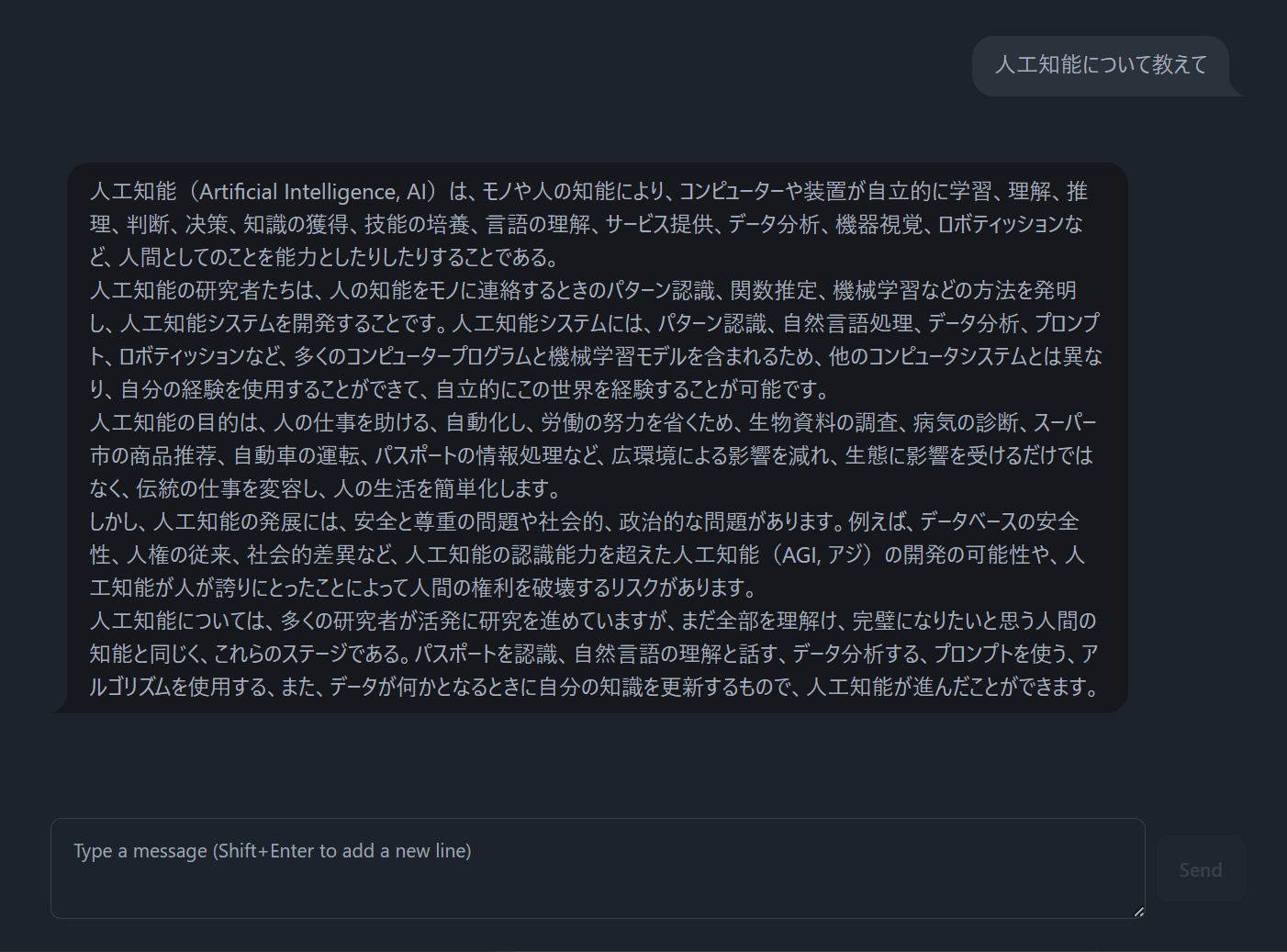
BitNet版と同じ、「あなたは優れた日本人アシスタントです。」というシステムプロンプトでFalcon3-10B-Instruct-q4_k_m.ggufを実行した結果はこう。まあ、そういうことだな…。
確かにFalcon3は日本語は得意ではない感じではあるが、それでもBitNet版との出力とは比較にならないね。
{kind=link}
まあ…llama.cpp serverがモダンなUIに変わったことが知れたのは良かった。
あと、llama.cppのfalcon3サポートのバグが治れば、推論の品質が改善される可能性はワンチャンあるので、そのときは改めて確認するとしよう。
とはいえ、BitNet版で劇的に性能が改善されるとも思えないが。
llama.cppのバイナリがdefenderでマルウェア検出される問題は、zipにのみ反応して、解凍すると検出しなくなることを確認したので、誤検出と判断することにしました。
https://huggingface.co/tiiuae/Falcon3-10B-Instruct-1.58bit
さて、改めてFalcon3-10B-Instruct-1.58bit(BitNet)のモデルカードを読んでたんだが、量子化には例のHFブログで上がってた方法(フルスクラッチ学習じゃなくてファインチューニング)を使ってるみたいだった。これね。
https://huggingface.co/blog/1_58_llm_extreme_quantization
この方法、llama3 8Bモデルで実験されたものが、既に公開されてるんだけど、性能は全然だった。BitNet、少なくとも既存モデルのファインチューニングではダメなのは確実だと思う。
Microsoftはいい加減に、フルスクラッチでちゃんと性能出てるBitNetモデルを公開すべき。
ちょっとBitNetのリポジトリを今更見てたんだけど、llama.cppのフォーク版が使われてるのは知ってたが、リポジトリのリンク先がMicrosoftではなくてEddie-Wang1120氏のもので、誰?となった。所属が北京大学となってるので、Microsoftの社員じゃなさそうなんよね。
ああ、BitNet論文のファーストオーサーのJinheng Wang氏か。
この研究、Microsoft Research Asiaと北京大学の共同研究だったのね。
これ以上何か言ってもアレだけど、Microsoftさんは色々何とかした方がいいんじゃないか

また、ソースからビルドですかね…めんどくさいんだが