フォロー

RT @bioshok3@twitter.com
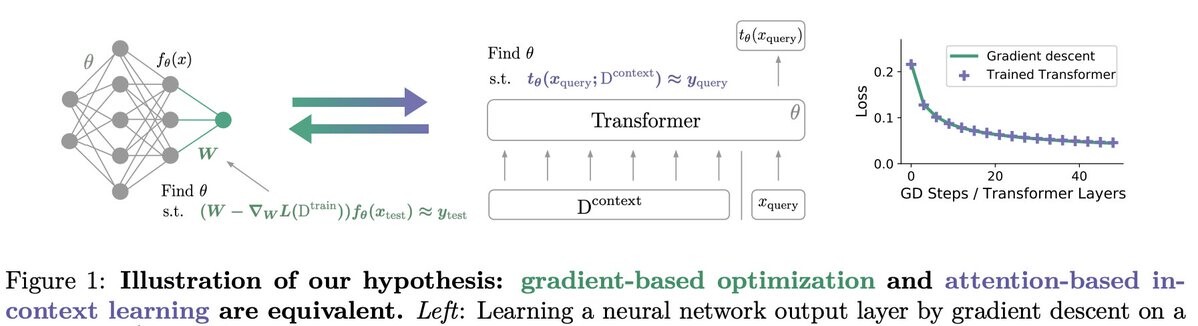
Googleやばすぎる仮説!
「勾配に基づく最適化と注意に基づくコンテキスト学習は等価である」
K個の勾配降下ステップ学習はK個の線形自己注意層を持つ学習済みTransformerと密接に整合。単一線形自己注意層から多層非線形モデルまで調査し類似。MLP追加でTransformer内での非線形回帰タスク解決可能! https://twitter.com/_akhaliq/status/1603607592529498112
{kind=link}
