
{kind=link}
{kind=link}
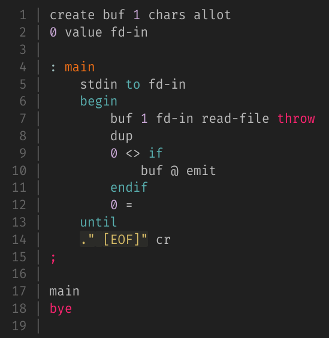
コメント残しておかないと何やってるか分からなくなって厳しい……慣れるのかなこれ。
ワードで細かく抽象化せよ、ワードの中はがんばって読め、という感じなのかな。
がんばるの大変そうなので(慣れるまでは?)コメント残す方向で進めた方がいいのかな。
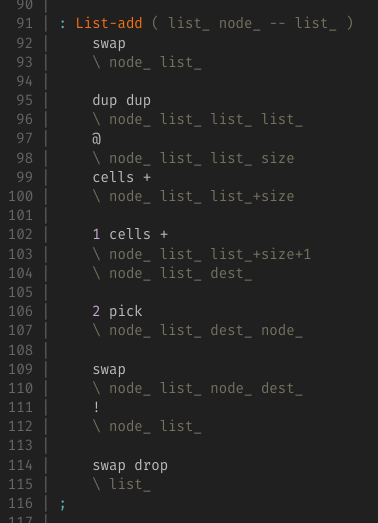
次はデータ構造(リスト)
[] と [1] が作れるようになった
{kind=link}
["fdsa"] が作れるようになった
[123, "fdsa"] が作れるようになった
[[]] が作れるようになった。
作れるようになったというか、作って JSON にシリアライズするところまで。入れ子なので再帰が必要で、ワードの定義に recursive を追加するだけで OK。
[1,"a",[2,"b"],3,"c"] が作れるようになった
["漢字"] もテスト通った。
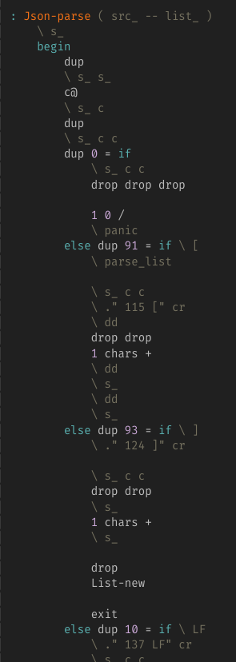
これでデータ構造整備+JSONシリアライズ編が終わり。次はJSONパース編。
{kind=link}
{kind=link}
[1] がパースできるようになった
整数を表示するときに余計なスペースが付かないようにするためにこれを使う必要がある……?
Formatted numeric output (Gforth Manual)
https://gforth.org/manual/Formatted-numeric-output.html
drop-1 〜 drop-N を作ったらだいぶスタック操作が楽になった(行儀が悪いかもしれないけどよく分かってない)
[1, "a", [2, "b"], 3, "c"] がパースできるようになった。
["漢字"] もすでにパースできているので、これでJSONパース編完了。
https://github.com/sonota88/mini-ruccola-forth/commit/0b682f15978ec9e529b37b722e9a8c23d0fa5aa0
レキサ編 その1
入力の最初の文字が 1 だったら [1, "int", "1"] を出力する。
https://github.com/sonota88/mini-ruccola-forth/commit/632152302793016a1681ddd892f1a95fe7c3eab7
レキサ編 その1(やりなおし)
入力の最初の文字が f だったら [] を出力する。
lexer 1 (mrcl_lexer.fs) · sonota88/mini-ruccola-forth@4dd9339
https://github.com/sonota88/mini-ruccola-forth/commit/4dd93395486b2e5cb06c58bbeea8ab4bec69e929
あーでも予約語でこれやると後でテスト通らなくなっちゃうのか。悩ましい。
空の main 関数(func main() {})がコンパイルできるようになった 👍
https://github.com/sonota88/mini-ruccola-forth/commit/ce6dfa53d0e4f1a9d4adbed6d84a2debf5680f8a
func main() {
var a;
return;
}
がコンパイルできるようになった
https://github.com/sonota88/mini-ruccola-forth/commit/c05cfa43696978da6f789c8f31c6d62f80d66470

あ、dup が1個余計になってますわ